Last week in Atlanta during the OpenStack Summit, I gave a talk on “Are enterprises ready for the OpenStack transformation” [slides|video]. In this talk, I suggest that OpenStack is a game changer, both by definition and because of how it’s following the AWS model, in the way enterprises should develop applications. I base this argument on the fact that OpenStack:
- forces the developers to change their mindset on what services the infrastructure offers and how the infrastructure should be consumed,
- encourages organizations to evolve toward a more agile model,
- and facilitates the adoption of devops principles,
The main business reasons behind OpenStack are: reduce time to market, accelerate your business reactivity, and ensure that you can solve faster, bigger and more complex problems with hyperscale issues. This is what drives most of eNovance’s customer engagements, and our tech blogs give somewhat a good overview of the variety of subjects we have been working on.
I call OpenStack a game changer because the environment it offers to host applications is somewhat hostile to old practices. How can you host a non self resilient application (which I call lazy apps, for lack of a better term) in an environment that does not offer functions such as VMWare’s DRS (or any VM level high availability functions), shared files system, shared block storage, or even active/passive virtual machine high availability?
Let’s be clear, OpenStack does not have these features, and that’s why applications must evolve in order to survive in this new hostile environment: VM Level high availability is a solution that will never warrants full data consistency; shared block storage does not scale beyond a handful of nodes (if even that many); shared file systems are a bottleneck for many applications. These are all well known show stoppers for horizontal scalability which, of course, is what OpenStack is all about. This means that lazy applications should either not be deployed on OpenStack, or rewritten to work on top of OpenStack (or any true IaaS cloud, for that matter).
Biology shows us that the evolution of species happens when their environments evolve. Many people know the story of the peppered moth butterfly and how it changed its dominant color over time. I strongly believe that similarly to butterflies, developers and organizations evolve when their environment changes, and OpenStack or AWS are exactly that: an environment change that forces an evolutionary process.
Win The Enterprise
During this year’s summit, a few meetings happened where fine people discussed how OpenStack would win the enterprise. I participated in some of them and heard many times that, in order to win the enterprise, OpenStack would have to evolve so as to be able to host most of the lazy apps. While this looks fine on an etherpad or during a discussion, I have the feeling that this set of features would quickly kill OpenStack, or at least OpenStack as we know it today.
OpenStack was designed as a platform for devops, by devops. The reason why OpenStack is where it is today is because hordes of devops joined to build that platform together. This means that it is meant for the developers’ teams that work jointly with their ops teams to deliver applications in rapid iterations. Many vendors, including Red Hat, learned at their own expense that the effort that they had put into building an open source VMWare equivalent became somewhat moot as OpenStack gained ground. They were forced to reconsider their strategy. The fact that VMWare is now starting to truly consider OpenStack is also quite telling.
If OpenStack starts to implement some of those non devops use cases, the risks are multiple:
- Loss of focus and therefore pertinence
- Loss of devops who are the key founders of and contributors to OpenStack
- Unmanageability due to project complexity and bloated features
For example, if we were to implement a feature similar to DRS, we are likely to require deep changes within Nova, Cinder and Neutron with possible impacts on multiple sub components. These changes could mean re-architecting some of those projects. I think that we should keep focusing on making the existing platform better before we start running after new ones that could have a damaging impact on stability and efficiency.
Let’s Offshore to Switzerland
When I consider the idea of migrating a lazy application to OpenStack as-is, I feel I’m being told of plans to offshore application hosting from the US to Switzerland. No offense intended to my Swiss friends, but if you know of a country where the average salaries are higher, I’ll happily change my example. Why do I think this? Simply because migrating a perfectly functioning application from its existing environment to OpenStack without any changes will have exactly the same effects as migrating the hosting of your apps to Switzerland.
Take a look at slide 13 of my presentation “Are enterprises ready for the OpenStack transformation” (screenshot below) to set your mind about the economics of a data center and note that the human cost is much more important than the cost of licenses. Even without touching its code, migrating those lazy apps as-is will carry a cost, which I know is not negligible.
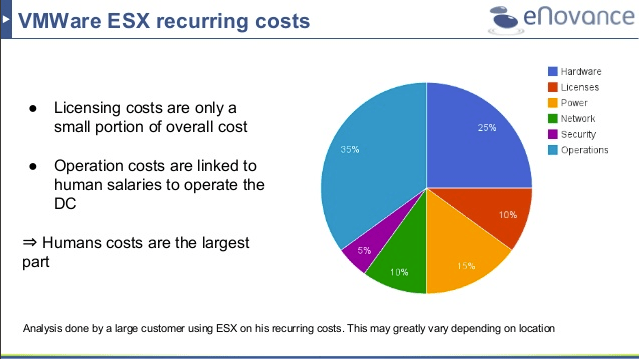
What benefits will running lazy apps as-is on top of OpenStack provide that offset the cost of migration? You won’t see any benefits from scalability, nor from better operations as we can assume that no change to the application means no added benefit from it being migrated. When asking around what were the expected benefits, the only answer I got was “to have unified data-center”. In other words, it would allow for cleaner operating procedure, simpler training of workforce and unified financial reporting. Here I see the power of marketing the idea that OpenStack is the API to the data-center and the simplification it brings. Yes, OpenStack does provide an abstraction of the data-center in the form of an API, but that does not mean that it should cover all of your data-center, or else we’ll be adding mainframe API into it, which, last time I checked, was not really part of the plan. 😉
Now, if you have not heard of products such as Cloudyn or CloudForms, I think it is a good time to do some market research and realize that there are many products and initiatives which are working on unifying multiple platforms from different standpoints, and I tend to think that those tools are better suited at providing solutions to the above mentioned benefits than changing OpenStack to shoehorn them in.
On the matter of training, my thoughts are even a bit simpler: obviously, current applications are already in operation, so the learning aspect should only be a concern for the (new) OpenStack platform. This will have to be done no matter what, right? So, with the exception of workplaces with unusually high turnover rates, I am not sure what the actual benefits would be in dropping the existing virtualization platforms to replace them with a cloud environment…
Application High Availability
This does not mean that we should not do everything we can to make application high availability simpler in OpenStack. For example, I wouldn’t be against having a service that uses the Nova APIs to monitor services or even entire VMs and automatically take action, such as starting another instance from the last snapshot of a cinder volume, creating additional instances and the like. To work, we would need to make sure that Nova correctly reports if an instance is alive or not, but would not change in any way the architecture of Nova. This could be used to do some things that could look a bit old fashion from a cloud paradigm standpoint, but would not endanger the very existence of OpenStack. Moreover, such service would actually be really useful to do things in the proper way. It would in fact provide a service to standardize automated monitoring (Monitoring as a Service – MONaaS – has been talked about lately), which I view as a good thing to have.
This is, in fact, the reason why I accepted to take the lead of the Application Availability subteam in the Win The Enterprise Initiative. I think we’ll have some very interesting and constructive discussions in that group, and am really looking forward to having them.
Keep OpenStack Weird
At this point, I hope you now understand why I think that we should keep OpenStack weird. Weird is the key to get better written applications, which autoscale and are self resilient. Weird is the way that your enterprise will become more agile in its way to do development and host applications. Weird is the way you’ll reduce your time to market and adapt more rapidly. Austin is where OpenStack started as well as the name of the first release, so reusing Austin’s motto (“Keep Austin Weird”) seems like a good idea. OpenStack aims to be THE cloud operating system. Let’s keep it that (weird) way, and not transform it into the everything virtualization, shall we?
As usual, the main intent of this post is to clarify my thoughts and I would welcome any comment on misconceptions or other shortcomings it might have, in the hopes to carry this conversation further and maybe even help make OpenStack better (or weirder) and use it as an enterprise transformation enabler.
[…] eNovance: Keep OpenStack Weird Last week in Atlanta during the OpenStack Summit, I gave a talk on “Are enterprises ready for the OpenStack transformation” [slides|video]. In this talk, I suggest that OpenStack is a game changer, both by definition and because of how it’s following the AWS model, in the way enterprises should develop applications. Read more. […]