A little more than 2 years ago, the Ceilometer project was launched inside the OpenStack ecosystem. Its main objective was to measure OpenStack cloud platforms in order to provide data and mechanisms for functionalities such as billing, alarming or capacity planning.
In this article, I would like to relate what I’ve been doing with other Ceilometer developers in the last 5 months. I’ve lowered my involvement in Ceilometer itself directly to concentrate on solving one of its biggest issue at the source, and I think it’s largely time to take a break and talk about it.
Ceilometer early design
For the last years, Ceilometer didn’t change in its core architecture. Without diving too much in all its parts, one of the early design decision was to build the metering around a data structure we called samples. A sample is generated each time Ceilometer measures something. It is composed of a few fields, such as the the resource id that is metered, the user and project id owning that resources, the meter name, the measured value, a timestamp and a few free-form metadata. Each time Ceilometer measures something, one of its components (an agent, a pollster…) constructs and emits a sample headed for the storage component that we call the collector.
This collector is responsible for storing the samples into a database. The Ceilometer collector uses a pluggable storage system, meaning that you can pick any database system you prefer. Our original implementation has been based on MongoDB from the beginning, but we then added a SQL driver, and people contributed things such as HBase or DB2 support.
The REST API exposed by Ceilometer allows to execute various reading requests on this data store. It can returns you the list of resources that have been measured for a particular project, or compute some statistics on metrics. Allowing such a large panel of possibilities and having such a flexible data structure allows to do a lot of different things with Ceilometer, as you can almost query the data in any mean you want.
The scalability issue
We soon started to encounter scalability issues in many of the read requests made via the REST API. A lot of the requests requires the data storage to do full scans of all the stored samples. Indeed, the fact that the API allows you to filter on any fields and also on the free-form metadata (meaning non
indexed key/values tuples) has a terrible cost in terms of performance (as pointed before, the metadata are attached to each sample generated by Ceilometer and is stored as is). That basically means that the sample data structure is stored in most drivers in just one table or collection, in
order to be able to scan them at once, and there’s no good “perfect” sharding solution, making data storage scalability painful.
It turns out that the Ceilometer REST API is unable to handle most of the requests in a timely manner as most operations are O(n) where n is the
number of samples recorded (see big O notation if you’re unfamiliar with it). That number of samples can grow very rapidly in an environment of thousands of metered nodes and with a data retention of several weeks. There is a few optimizations to make things smoother in general cases fortunately, but as soon as you run specific queries, the API gets barely usable.
During this last year, as the Ceilometer PTL, I discovered these issues first hand since a lot of people were feeding me back with this kind of testimony. We engaged several blueprints to improve the situation, but it was soon clear to me that this was not going to be enough anyway.

Thinking outside the box

Unfortunately, the PTL job doesn’t leave him enough time to work on the actual code nor to play with anything new. I was coping with most of the project bureaucracy and I wasn’t able to work on any good solution to tackle the issue at its root. Still, I had a few ideas that I wanted to try and as soon as I stepped down from the PTL role, I stopped working on Ceilometer itself to try something new and to think a bit outside the box.
When one takes a look at what have been brought recently in Ceilometer, they can see the idea that Ceilometer actually needs to handle 2 types of data: events and metrics.
Events are data generated when something happens: an instance start, a volume is attached, or an HTTP request is sent to an REST API server. These
are events that Ceilometer needs to collect and store. Most OpenStack components are able to send such events using the notification system built
into oslo.messaging.
Metrics is what Ceilometer needs to store but that is not necessarily tied to an event. Think about an instance CPU usage, a router network bandwidth
usage, the number of images that Glance is storing for you, etc… These are not events, since nothing is happening. These are facts, states we need to meter.
Computing statistics for billing or capacity planning requires both of these data sources, but they should be distinct. Based on that assumption, and the fact that Ceilometer was getting support for storing events, I started to focus on getting the metric part right.
I had been a system administrator for a decade before jumping into OpenStack development, so I know a thing or two on how monitoring is done in this area, and what kind of technology operators rely on. I also know that there’s still no silver bullet – this made it a good challenge.
The first thing that came to my mind was to use some kind of time-series database, and export its access via a REST API – as we do in all OpenStack
services. This should cover the metric storage pretty well.
Cooking Gnocchi
![]() At the end of April 2014, this led met to start a new project code-named Gnocchi. For the record, the name was picked after confusing so many times the OpenStack Marconi project, reading OpenStack Macaroni instead. At least one OpenStack project should have a “pasta” name, right?
At the end of April 2014, this led met to start a new project code-named Gnocchi. For the record, the name was picked after confusing so many times the OpenStack Marconi project, reading OpenStack Macaroni instead. At least one OpenStack project should have a “pasta” name, right?
The point of having a new project and not send patches on Ceilometer, was that first I had no clue if it was going to make something that would be any better, and second, being able to iterate more rapidly without being strongly coupled with the release process.
The first prototype started around the following idea: what you want is to meter things. That means storing a list of tuples of (timestamp, value) for it. I’ve named these things “entities”, as no assumption are made on what they are. An entity can represent the temperature in a room or the CPU usage of an instance. The service shouldn’t care and should be agnostic in this regard.
One feature that we discussed for several OpenStack summits in the Ceilometer sessions, was the idea of doing aggregation. Meaning, aggregating samples over a period of time to only store a smaller amount of them. These are things that time-series format such as the RRDtool have been doing for a long time on the fly, and I decided it was a good trail to follow.
I assumed that this was going to be a requirement when storing metrics into Gnocchi. The user would need to provide what kind of archiving it would need: 1 second precision over a day, 1 hour precision over a year, or even both.
The first driver written to achieve that and store those metrics inside Gnocchi was based on whisper. Whisper is the file format used to store metrics for the Graphite project. For the actual storage, the driver uses Swift, which has the advantages to be part of OpenStack and scalable.
Storing metrics for each entities in a different whisper file and putting them in Swift turned out to have a fantastic algorithm complexity: it was O(1). Indeed, the complexity needed to store and retrieve metrics doesn’t depends on the number of metrics you have nor on the number of things you
are metering. Which is already a huge win compared to the current Ceilometer collector design.
However, it turned out that whisper has a few limitations that I was unable to circumvent in any manner. I needed to patch it to remove a lot of its assumption about manipulating file, or that everything is relative to now (time.time()). I’ve started to hack on that in my own fork, but… then everything broke. The whisper project code base is, well, not the state of the art, and have 0 unit test. I was starring at a huge effort to transform whisper into the time-series format I wanted, without being sure I wasn’t going to break everything (remember, no test coverage).
I decided to take a break and look into alternatives, and stumbled upon Pandas, a data manipulation and statistics library for Python. Turns out that Pandas support time-series natively, and that it could do a lot of the smart computation needed in Gnocchi. I built a new file format leveraging Pandas for computing the time-series and named it carbonara (a wink to both the Carbon project and pasta, how clever!). The code is quite small (a third of whisper‘s, 200 SLOC vs 600 SLOC), does not have many of the whisper limitations and… it has test coverage. These Carbonara files are then, in the same fashion, stored into Swift containers.
Anyway, Gnocchi storage driver system is designed in the same spirit that the rest of OpenStack and Ceilometer storage driver system. It’s a plug-in system with an API, so anyone can write their own driver. Eoghan Glynn has already started to write a InfluxDB driver, working closely with the upstream developer of that database. Dina Belova started to write an OpenTSDB driver. This helps to make sure the API is designed directly in the right way.
Handling resources
Measuring individual entities is great and needed, but you also need to link them with resources. When measuring the temperature and the number of a people in a room, it is useful to link these 2 separate entities to a resource, in that case the room, and give a name to these relations, so one is able to identify what attribute of the resource is actually measured. It is also important to provide the possibility to store attributes on these resources, such as their owners, the time they started and ended their existence, etc.
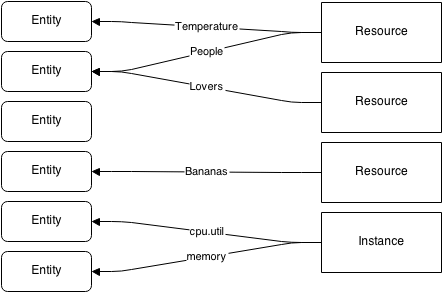 Once this list of resource is collected, the next step is to list and filter them, based on any criteria. One might want to retrieve the list of resources created last week or the list of instances hosted on a particular node right now.
Once this list of resource is collected, the next step is to list and filter them, based on any criteria. One might want to retrieve the list of resources created last week or the list of instances hosted on a particular node right now.
Resources also need to be specialized. Some resources have attributes that must be stored in order for filtering to be useful. Think about an instance name or a router network.
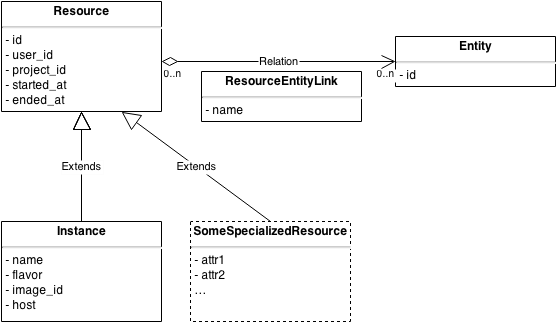
All of these requirements led to to the design of what’s called the indexer. The indexer is responsible for indexing entities, resources, and
link them together. The initial implementation is based on SQLAlchemy and should be pretty efficient. It’s easy enough to index the most requested attributes (columns), and they are also correctly typed.
We plan to establish a model for all known OpenStack resources (instances, volumes, networks, …) to store and index them into the Gnocchi indexer in order to request them in an efficient way from one place. The generic resource class can be used to handle generic resources that are not tied to OpenStack. It’d be up to the users to store extra attributes.
Dropping the free form metadata we used to have in Ceilometer makes sure that querying the indexer is going to be efficient and scalable.
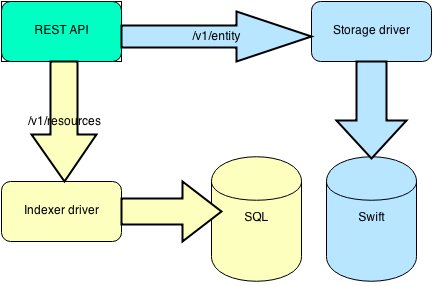
REST API
All of this is exported via a REST API that was partially designed and documented in the Gnocchi specification in the Ceilometer repository;
though the spec is not up-to-date yet. We plan to auto-generate the documentation from the code as we are currently doing in Ceilometer.
The REST API is pretty easy to use, and you can use it to manipulate entities and resources, and request the information back.
Roadmap & Ceilometer integration
All of this plan has been exposed and discussed with the Ceilometer team during the last OpenStack summit in Atlanta in May 2014, for the Juno release. I led a session about this entire concept, and convinced the team that using Gnocchi for our metric storage would be a good approach to solve the Ceilometer collector scalability issue.
It was decided to conduct this project experiment in parallel of the current Ceilometer collector for the time being, and see where that would lead the project to.
Early benchmarks
Some engineers from Mirantis did a few benchmarks around Ceilometer and also against an early version of Gnocchi, and Dina Belova presented them to us during the mid-cycle sprint we organized in Paris in early July.
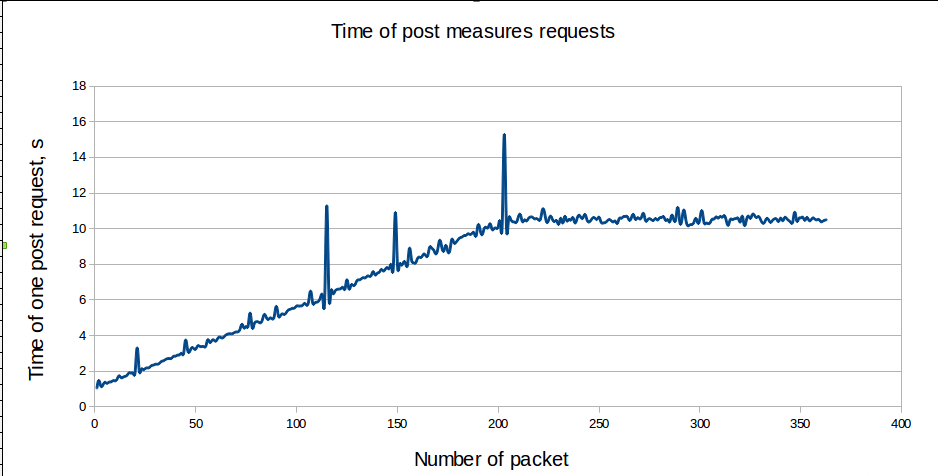
The following graph sums up pretty well the current Ceilometer performance issue. The more you feed it with metrics, the more slow it becomes.
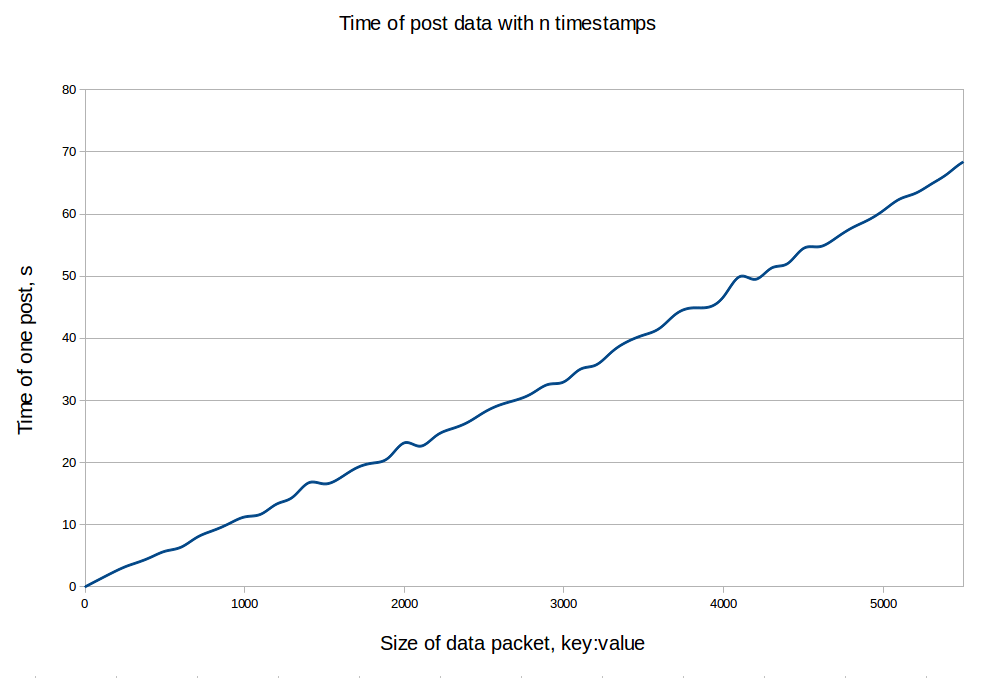
For Gnocchi, while the numbers themselves are not fantastic, what is interesting is that all the graphs below show that the performances are stable without correlation with the number of resources, entities or measures. This proves that, indeed, most of the code is built around a complexity of O(1), and not O(n) anymore.
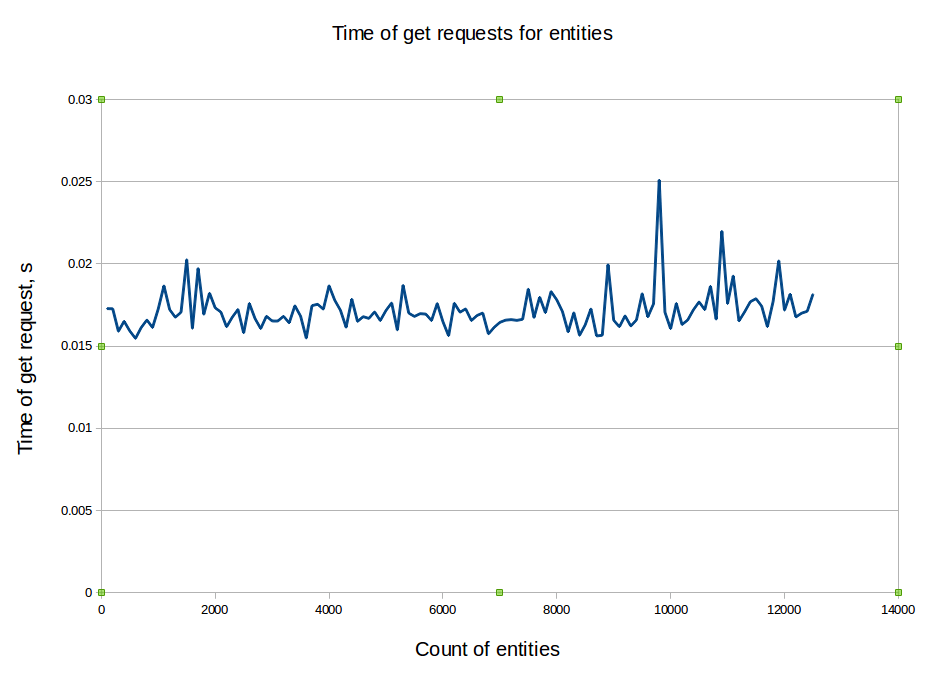
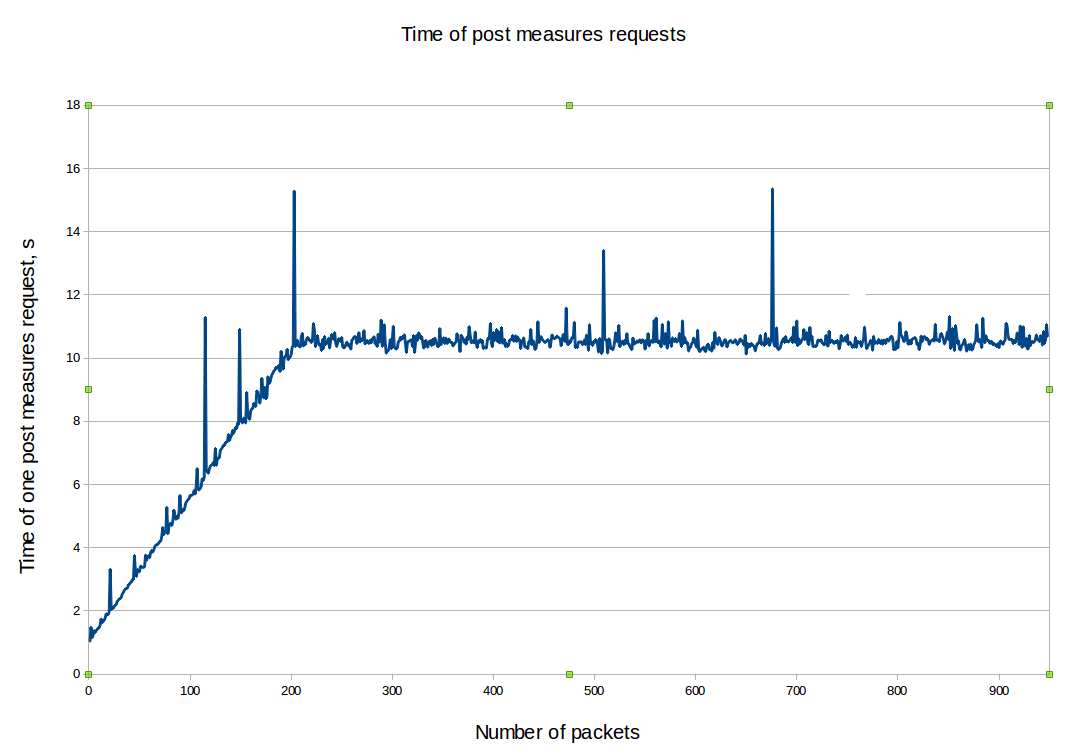
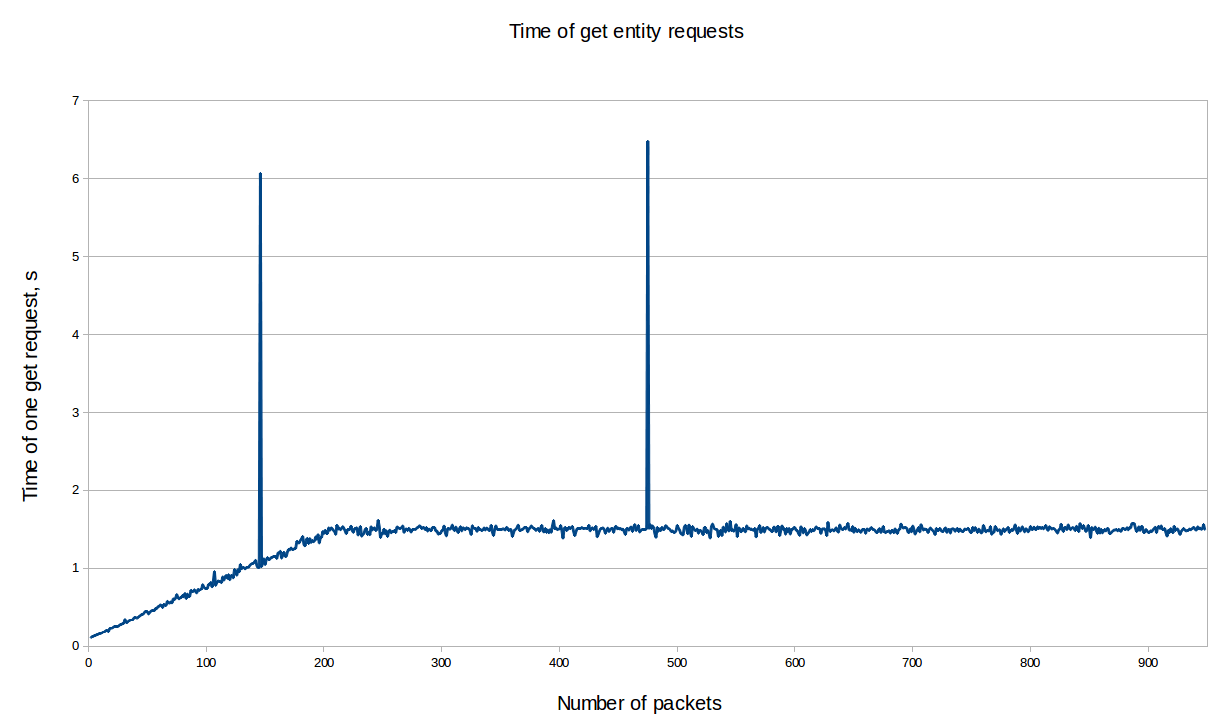
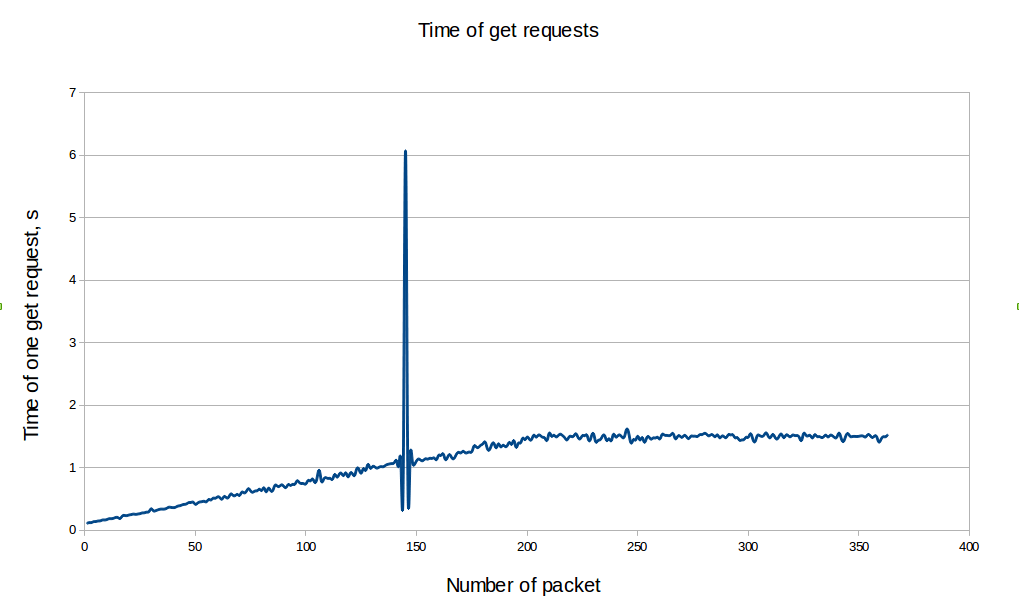
Next steps
While the Juno cycle is being wrapped-up for most projects, including Ceilometer, Gnocchi development is still ongoing. Fortunately, the composite
architecture of Ceilometer allows a lot of its features to be replaced by some other code dynamically. That, for example, enables Gnocchi to provides a Ceilometer dispatcher plugin for its collector, without having to ship the actual code in Ceilometer itself. That should help the development of Gnocchi to not be slowed down by the release process for now.
The Ceilometer team aims to provide Gnocchi as a sort of technology preview with the Juno release, allowing it to be deployed along and plugged with Ceilometer. We’ll discuss how to integrate it in the project in a more permanent and strong manner probably during the OpenStack Summit for Kilo that will take place next November in Paris.
Great article. Intelligible even to the novice. Thank you! Happy Holidays!
Very nice concept and great article! Thanks!
I see that this article is similar to the undated wiki page (https://wiki.openstack.org/wiki/Gnocchi). Any updates?
[…] As presented by Julien Danjou, Gnocchi is designed to store metric metadata into an indexer (usually a SQL database) and store the metric measurements into another backend. The default backend creates timeseries using Carbonara (a pandas based library) and stores them into Swift. […]
[…] A few months ago, I wrote a long post about what I called back then the “Gnocchi experiment“. […]