As presented by Julien Danjou, Gnocchi is designed to store metric metadata into an indexer (usually a SQL database) and store the metric measurements into another backend. The default backend creates timeseries using Carbonara (a pandas based library) and stores them into Swift.
The storage Gnocchi backend is pluggable, and not all deployments install Swift, so I have decided to write another backend, I have chosen Ceph because it’s close to Swift in the way we use it in Gnocchi and scale well when we have many objects stored too. Now, let’s see what I need to do to reach this goal.
Storage driver interface
The current metric storage driver interface to implement looks like this:
- create_metric(metric, archive_policy)
- add_measures(metric, measures)
- get_measures(metric, from_timestamp=None, to_timestamp=None, aggregation=’mean’)
- delete_metric(metric)
- get_cross_metric_measures(metrics, from_timestamp=None, to_timestamp=None, aggregation=’mean’, needed_overlap=None)
Cool, not so many methods to implement, we have to:
- initialize a new metric with the defined archive policy, how many point we keep, the frequency, the aggregation methods…
- add new measures to this metric, a measure is just a timestamp associated with a value. The storage driver doesn’t care about the nature/unit of the metric. This is actually stored into indexer database.
- retrieve the aggregated measurements of a metric This returns a list of tuple(timestamp, granularity, value)
- delete a metric with all its measures
- get the aggregation acrossmultiple metrics. Theisreturns a list of tuple(timestamp, granularity, value), too
By default, the interface doesn’t enforce the time series format, so we are free to store the metric archive policy and the measurements in any format we want. But actually, timeseries fit well with this interfaces. This is why it’s possible to write a OpenTSDB or a InfluxDB driver.
We currently have a driver for Swift, so let’s go to write the driver for Ceph. It should be pretty straightforward, as it’s also a key value store.
The case of a Carbonara based storage driver
By chance, if the storage driver is a key value store, we don’t have to implement all of these methods. Gnocchi provide an other layer named Carbonara that do all the timeseries stuffs for us. The only thing we need to do is to store a blob for a particular metric and a particular aggregation.
A storage driver that uses Carbonara has to inherit from gnocchi.storage._carbonara.CarbonaraBasedStorage and to implement these methods:
- _create_metric_container(metric)
- _store_metric_measures(metric, aggregation, data)
- _get_measures(metric, aggregation)
- delete_metric(self, metric)
- _lock(metric, aggregation)
Now, we have:
- to create a container (_create_metric_container), this method can make any initialization for a metric (the Swift driver create a container per metric) and raise ‘storage.MetricAlreadyExists’ is the metric already exists.
- to store the blob created by carbonara for the aggregation of a metric, (the Swift driver creates/updates an object named with the aggregation method name into the metric container)
- to return the blob for the aggregation of a metric
- to delete all blobs associated to a metric
- lock a Carbonara blob, here, we can just use the CarbonaraBasedStorageToozLock class, that use Tooz and do all the locking stuffs for us.
Note that we don’t care about aggregation across metric, Carbonara does this for us too.
How will we do that for Ceph? Ceph doesn’t have the notion of container, we just have to choose a format for the object name such as “gnocchi_<metric_name>_<aggregation_method>”, and then stats/stores/retrieves/deletes the Carbonara blobs.
How does it look like in Python
Connect to Ceph with the RADOS protocol, define the object name format, use the Tooz lock helper and create a helper to prepare the Ceph object name.
import rados
from gnocchi import storage
from gnocchi.storage import _carbonara
class CephStorage(_carbonara.CarbonaraBasedStorage):
def __init__(self, conf):
super(CephStorage, self).__init__(conf)
self.pool = 'my_gnocchi_pool'
self.rados = rados.Rados(conffile='/etc/ceph/ceph.conf')
self.rados.connect()
self._lock = _carbonara.CarbonaraBasedStorageToozLock(conf)
@staticmethod
def _get_object_name(metric, aggregation):
return "gnocchi_%s_%s" % (metric, aggregation)
def _get_ioctx(self):
return self.rados.open_ioctx(self.pool)Then, check if the object already exists or not andraise the appropriate exception if so (storage.MetricAlreadyExists):
def _create_metric_container(self, metric):
aggregation = self.aggregation_types[0]
name = self._get_object_name(metric, aggregation)
with self._get_ioctx() as ioctx:
try:
size, mtime = ioctx.stat(name)
except rados.ObjectNotFound:
return
raise storage.MetricAlreadyExists(metric)Store the Carbonara blob in a Ceph object named gnocchi_<metric_name>_<aggregation_method>
def _store_metric_measures(self, metric, aggregation, data):
name = self._get_object_name(metric, aggregation)
with self._get_ioctx() as ioctx:
ioctx.write_full(name, data)Retrieve the Carbonara blob associated with this aggregation and metric:
def _get_measures(self, metric, aggregation):
try:
with self._get_ioctx() as ioctx:
name = self._get_object_name(metric, aggregation)
offset = 0
content = b''
while True:
data = ioctx.read(name, offset=offset)
if not data:
break
content += data
offset += len(content)
return content
except rados.ObjectNotFound:
raise storage.MetricDoesNotExist(metric)Delete all stuffs behind a metric:
def delete_metric(self, metric):
with self._get_ioctx() as ioctx:
try:
for aggregation in self.aggregation_types:
name = self._get_object_name(metric, aggregation)
ioctx.remove_object(name)
except rados.ObjectNotFound:
raise storage.MetricDoesNotExist(metric)Indeed, this is really straightforward, we have just written glue to create/update/delete object with the blob generated by Carbonara. At this point we have a working storage driver with ~ 50 lines of code. I’m pretty sure that writting a Cassandra or a Riak storage driver would be simple too.
Carbonara based storage driver lock mechanism.
The update workflow of this driver is: get the timeserie data from the key/value store update it with the new values store it in the key/value store.
Since we can deploy multiple Gnocchi API workers,we have to ensure the consistency of this workflow. To do that, the Carbonara based storage driver have to lock the timeserie it is updating across all the Gnocchi API workers. The Swift driver use Tooz to do that (and the Ceph example above too).
But with Ceph we can go deeper and replace the Tooz lock helper by the Ceph object lock.
To do that instead of doing:
self._lock = _carbonara.CarbonaraBasedStorageToozLock(conf)I have implemented the ‘_lock(metric, aggregation)’ method, this method have to returns a context manager that lock Carbonara blob in __enter__ and release it in __exit__:
For ceph is looks like this:
@contextlib.contextmanager
def _lock(self, metric, aggregation):
name = self._get_object_name(metric, aggregation)
with self._get_ioctx() as ctx:
ctx.lock_exclusive(name, 'lock', 'gnocchi')
try:
yield
finally:
ctx.unlock(name, 'lock', 'gnocchi')Note: the in tree gnocchi code is quite different to support older version of the Python rados
Then we have to tweak a bit the _create_metric_container and _get_measures, because creating an object lock on an unexisting object in Ceph, create the object with no content.
So in _create_metric_container replaces:
size, mtime = ioctx.stat(name)by
size, mtime = ioctx.stat(name)
if size == 0:
returnAnd in _get_measures replaces:
return contentby
if len(content) == 0:
raise storage.MetricDoesNotExist(metric)
return contentWith this few additional lines, we now have the ceph storage driver that use the object locking mechanism of ceph.
The in tree ceph driver of gnocchi looks like that with some compatibility stuffs for old python-ceph library and some additional configuration options (ceph keyring/userid/pool).
Unit tests
To test the driver we don’t have to rewrite everything. Gnocchi uses testscenarios to run a suite of tests on each drivers, so we can just add the new storage driver to the list.
In https://github.com/stackforge/gnocchi/blob/master/gnocchi/tests/base.py we add:
storage_backends = [
('null', dict(storage_engine='null')),
('swift', dict(storage_engine='swift')),
...
('ceph', dict(storage_engine='ceph')),
]Then, we have two solutions:
- if this is possible, we can create a script to setup the backend, like we did for PostgreSQL or MySQL.
- if not, we can just mock the underlying Python module, like this is done for Swift (that mock python-swiftclient).
For the Ceph driver, I have used the second solution, because installing and setuping Ceph into the Openstack Infra CI, it not really easy. You can found the mock of this library here.
This mocked library is loaded here like this:
self.useFixture(mockpatch.Patch('gnocchi.storage.ceph.rados', FakeRadosModule()))Nothing else, the driver have unit tests now.
Now test it!
To do it, I setup a devstack VM for swift with the following devstack configuration:
SWIFT_REPLICAS=1
enable_plugin gnocchi https://github.com/stackforge/gnocchi
enable_service key,gnocchi-api,s-proxy,s-object,s-container,s-accountAnd a devstack VM for ceph with:
enable_plugin gnocchi https://github.com/stackforge/gnocchi
enable_service key,gnocchi-api,ceph
And then for each, I run the gnocchi perf_tools that measures the time to put/get measurements. I use 10 clients in parallel that POST 100 times a batch of 100 measurements, the value of each measurements is always 100, to have exactly the same data generated for each backend.
I run this workload with
mkdir result_swift
n=10 parallel --progress -j $n python ./tools/duration_perf_test.py --result result_swift/client{}.. code-block:: $(seq 0 $n)And after on my ceph VM:
mkdir result_ceph
n=10 parallel --progress -j $n python ./tools/duration_perf_test.py --result result_ceph/client{}.. code-block:: $(seq 0 $n)Take a looks of the result:
python ./tools/duration_duration_perf_analyse.py result_swift
* get_measures:
Duration
mean 0.03918
std 0.02060
min 0.01000
max 0.13000
...
* write_measures:
Duration
mean 4.058136
std 2.034822
min 0.550000
max 9.350000
...python ./tools/duration_perf_analyse.py result_ceph
* get_measures:
Duration
mean 0.037790
std 0.029531
min 0.010000
max 0.310000
...
* write_measures:
Duration
mean 5.523090
std 2.643746
min 0.500000
max 9.400000
...The tools also generates csv files that we can use to make some graphs:
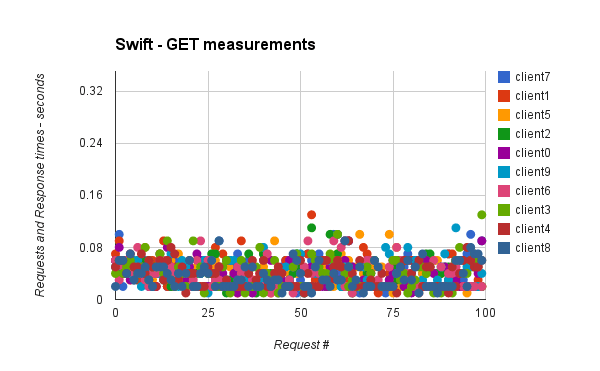
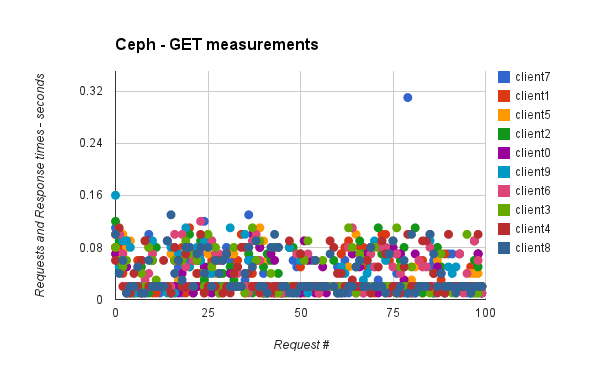

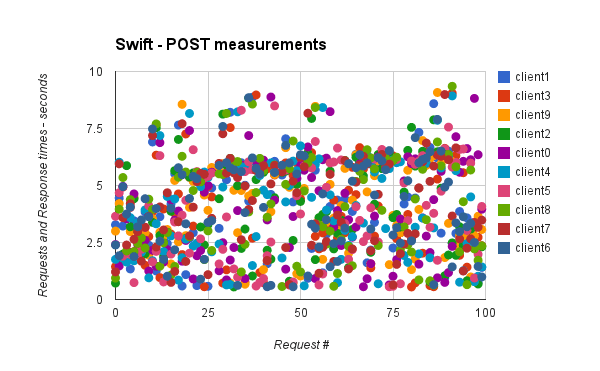
We don’t see a significant difference between swift and ceph here, but results come from a all-in-one vm, I could be cool to do that on a real swift/ceph cluster with more clients in parallel and during much times, to see the limit of each backends. But this is enough to see that the time to get/write measurements doesn’t change over the times, and that is good things.