A while ago, I had made a quick article/demo of how to use Ceilometer instead of the built-in emulated Amazon CloudWatch resources of Heat.
To extend on the previous post, when you create a stack, instances of the stack generated notifications that were received by Ceilometer and converted into samples to be written to a database; usually MongoDB. On the other end, Heat created some alarms using the Ceilometer API to trigger the Heat autoscaling actions. These alarms defined some rules against statistics based on the previously recorded samples. These statistics were computed on the fly when the alarms were evaluated.
The main issue with this setup was that the performance for evaluating all the defined alarms was directly tied to the number of alarms and to the complexity of computing the statistics. The computation of a statistic would result in a map reduce in MongoDB. Therefore, when there were additional ceilometer-alarm-evaluator workers and nodes there would be additional MongoDB map reduce operations in parallel.
In order to reduce the time between alarm evalutions, more workers and nodes are required as well as a solid MongoDB configuration.
Starting with Kilo, Ceilometer has a new dispatcher driver: Gnocchi. Instead of writing samples directly into the database, Ceilometer converts them into Gnocchi elements (resource, metric and measurement) and posts them on the Gnocchi REST API.
Contrary to the current Ceilometer database dispatcher, Gnocchi aggregates what it receives, and doesn’t compute anything when you want to retrieve statistics. There are no more on the fly computations! You can find more information about that in Julien Danjou’s articles “Ceilometer, the Gnocchi experiment” and “Gnocchi first release”,
On the Ceilometer alarm side, the system now has some new alarm rule types dedicated to Gnocchi. Instead of describing rules that would trigger computing statistics, we define rules that will get the result of pre-computed statistics.
That makes the Ceilometer alarm evaluators much more performant. The evaluation of an alarm just result in one single HTTP call. On the Gnocchi side, when using the Swift backend, this will break down into one SQL request to check RBAC, and another HTTP call to Swift to retrieve the result. No more on-the-fly statistics computation of any kind.
The side effect of that system is that you need to tell Gnocchi how you want to pre compute/aggregate data, that’s all.
Playing with all of that with Heat
Devstack setup
Boot a VM, install devstack, configure your stack. Enable all Gnocchi/Heat/Ceilometer services in your localrc:
enable_plugin gnocchi https://github.com/openstack/gnocchi master enable_service q-lbaas enable_service ceilometer-api,ceilometer-collector enable_service ceilometer-acompute enable_service ceilometer-alarm-notifier,ceilometer-alarm-evaluator enable_service heat,h-api,h-eng,h-api-cfn enable_service gnocchi-api IMAGE_URLS="http://ftp.free.fr/mirrors/fedora.redhat.com/fedora/linux/releases/21/Cloud/Images/x86_64/Fedora-Cloud-Base-20141203-21.x86_64.qcow2" GNOCCHI_COORDINATOR_URL=redis://localhost:6379?timeout=5
Enable an eager processing of the ceilometer pipeline (every 10sec):
CEILOMETER_PIPELINE_INTERVAL=10
Add the ‘last’ aggregation method to the default archive_policy of Gnocchi:
[[post-config|$GNOCCHI_CONF]] [archive_policy] default_aggregation_methods = mean,min,max,sum,std,median,count,last,95pct
And go!
$ ./stack.sh
Let’s look at some important configuration done by devstack to enable Gnocchi with MySQL and file as backend.
In Ceilometer, the database dispatcher is replaced by Gnocchi with the following configuration:
[DEFAULT] dispatcher = gnocchi [dispatcher_gnocchi] filter_project = gnocchi_swift filter_service_activity = True archive_policy = low url = http://192.168.3.51:8041
Note that it configures a filter to filter out all samples generated by
Gnocchi. Otherwise each time we write to Swift that will generate samples to
write again to Swift and this will create a storm of samples that grows
indefinitely. The filter breaks this infinite loop.
Also for alarming, devstack sets the Gnocchi API endpoint:
[alarms] gnocchi_url = http://192.168.3.51:8041
On Gnocchi side, the file driver has been configured for the storage and the SQL database for the indexer:
[storage] driver = file file_basepath = /opt/gnocchi/ [indexer] url = mysql://root:password@127.0.0.1/gnocchi?charset=utf8
If Swift have been has been chosen as storage backend you will get:
[storage] driver = swift swift_authurl = http://192.168.3.51:5000/v2.0/ swift_auth_version = 2 swift_tenant_name = gnocchi_swift swift_key = password swift_user = gnocchi_swift
Note: The default devstack configuration of Swift can’t handle the load generated by Gnocchi and Ceilometer, The number of swift workers needs to be increased.
Heat stack setup
Once everything is up, we can create our first stack with these templates :
$ netid="dc88aba8-e062-4e88-af2b-3799d37b0110" $ subnetid="49fb0c92-c5da-42fa-b7ec-a9967976d4d0" $ pubnetid="faa263ef-bedd-445b-9f2a-99857b45956e" $ heat stack-create --template-file autoscaling_gnocchi.yaml --parameters "subnet_id=$subnetid;external_network_id=$pubnetid;network_id=$netid;key=sileht" gnocchi +--------------------------------------+------------+--------------------+----------------------+ | id | stack_name | stack_status | creation_time | +--------------------------------------+------------+--------------------+----------------------+ | bab1a943-6647-4de3-bfd9-5e0630ccf409 | gnocchi | CREATE_IN_PROGRESS | 2015-04-22T08:11:48Z | +--------------------------------------+------------+--------------------+----------------------+ $ heat resource-list gnocchi +-----------------------------+----------------------------------------------+----------------------------------------------------+-----------------+----------------------+ | resource_name | physical_resource_id | resource_type | resource_status | updated_time | +-----------------------------+----------------------------------------------+----------------------------------------------------+-----------------+----------------------+ | lb | | OS::Neutron::LoadBalancer | CREATE_COMPLETE | 2015-04-22T13:51:57Z | | asg | 655e7e87-9e32-41aa-b49c-950512aa519b | OS::Heat::AutoScalingGroup | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | cpu_alarm_high | 1ebb71cb-1636-405d-9ca6-300622af9940 | OS::Ceilometer::GnocchiAggregationByResourcesAlarm | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | cpu_alarm_low | ef2485b4-f3a2-4dbc-8195-6ef9063d0b73 | OS::Ceilometer::GnocchiAggregationByResourcesAlarm | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | database_password | gnocchi2-database_password-de6upz5liayi | OS::Heat::RandomString | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | database_root_password | gnocchi2-database_root_password-qbz5ukcjuocf | OS::Heat::RandomString | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | db | 9e9cc43c-0db0-4191-b886-8d9930a7a558 | OS::Nova::Server | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | lb_floating | 12296e32-8c16-4eed-9272-1400e160cec2 | OS::Neutron::FloatingIP | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | monitor | fbb55426-241a-4f1e-9e31-004b3a2db4a3 | OS::Neutron::HealthMonitor | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | pool | 0a5360fc-378f-4f89-8b92-cba81b05d859 | OS::Neutron::Pool | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | web_server_scaledown_policy | d72492aebf214454a38526fec2b5debe | OS::Heat::ScalingPolicy | CREATE_COMPLETE | 2015-04-22T13:51:58Z | | web_server_scaleup_policy | db53a21a207e48c2ac9916285ce85a55 | OS::Heat::ScalingPolicy | CREATE_COMPLETE | 2015-04-22T13:51:58Z | +-----------------------------+----------------------------------------------+----------------------------------------------------+-----------------+----------------------+
Obviouly you will need to change the networks ids to match your own environment.
Taking a quick look at an alarm definition in the Heat templates:
cpu_alarm_high:
type: OS::Ceilometer::GnocchiAggregationByResourcesAlarm
properties:
description: Scale-up if the last CPU > 50% for 1 minute
metric: cpu_util
threshold: 50
comparison_operator: gt
alarm_actions:
- {get_attr: [web_server_scaleup_policy, alarm_url]}
resource_type: instance
aggregation_method: last
granularity: 300
evaluation_periods: 1
query:
str_replace:
template: '{"=": {"server_group": "stack_id"}}'
params:
stack_id: {get_param: "OS::stack_id"}
The alarm definition looks almost like the legacy Ceilometer one. The query is identical to the POST data of a search API request in Gnocchi
Also, the Gnocchi resource attributes are strictly defined, “server_group” is one of the extended attributes of an instance. And of course the ‘last CPU’ is just for demo.
Now, take a look to the created Nova instances:
$ nova list +--------------------------------------+-------------------------------------------------------+--------+------------+-------------+---------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+-------------------------------------------------------+--------+------------+-------------+---------------------+ | 757ca456-a436-4770-9ce2-029d2b717340 | gn-qxjx-h26oilfiz4mu-ao3cn5ctyin2-server-ze4ulgwkg77y | ACTIVE | - | Running | admpriv=192.168.0.7 | | 9e9cc43c-0db0-4191-b886-8d9930a7a558 | gnocchi2-db-6hlmbgeikp56 | ACTIVE | - | Running | admpriv=192.168.0.6 | +--------------------------------------+-------------------------------------------------------+--------+------------+-------------+---------------------+
Then in the terminal of the first instance (gn-qxjx-h26oilfiz4mu-ao3cn5ctyin2-server-ze4ulgwkg77y), I generated some load:
$ yum install stress $ stress --cpu 2 --timeout 600
Some minutes later, in Nova, I can see the new instance booted by Heat:
$ nova list +--------------------------------------+-------------------------------------------------------+--------+------------+-------------+---------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+-------------------------------------------------------+--------+------------+-------------+---------------------+ | 53b5f608-320c-4ead-82e2-bde0b500ebd8 | gn-9395-d70e19b0106b-b781771ab85d-server-a855902efk26 | ACTIVE | - | Running | admpriv=192.168.0.8 | | 757ca456-a436-4770-9ce2-029d2b717340 | gn-qxjx-h26oilfiz4mu-ao3cn5ctyin2-server-ze4ulgwkg77y | ACTIVE | - | Running | admpriv=192.168.0.7 | | 9e9cc43c-0db0-4191-b886-8d9930a7a558 | gnocchi2-db-6hlmbgeikp56 | ACTIVE | - | Running | admpriv=192.168.0.6 | +--------------------------------------+-------------------------------------------------------+--------+------------+-------------+---------------------+
The Ceilometer alarms have been created:
$ ceilometer alarm-show 51e11820-7f72-4a69-bd93-f3b686e0430c
+---------------------------+--------------------------------------------------------------------------+
| Property | Value |
+---------------------------+--------------------------------------------------------------------------+
| aggregation_method | last |
| alarm_actions | [u'http://192.168.3.51:8000/v1/signal/arn%3Aopenstack%3Aheat%3A%3Abf9098 |
| | 1532444f91b70d3f58e9fd1b3d%3Astacks%2Fgnocchi2%2Fd65c891b-4543-4d1e-aa39 |
| | -4d446ce4a3e8%2Fresources%2Fweb_server_scaleup_policy?Timestamp=2015-04- |
| | 23T14%3A50%3A52Z&SignatureMethod=HmacSHA256&AWSAccessKeyId=2c7195e4a6414 |
| | 0719131680bf8a96d4b&SignatureVersion=2&Signature=hbQCSYsjd2f9%2FeH1mKZps |
| | zI4ec20Ot0mVLBtCbkLpDU%3D'] |
| alarm_id | 51e11820-7f72-4a69-bd93-f3b686e0430c |
| comparison_operator | gt |
| description | Scale-up if the last CPU > 50% for 1 minute |
| enabled | True |
| evaluation_periods | 1 |
| granularity | 300 |
| insufficient_data_actions | None |
| metric | cpu_util |
| name | gnocchi2-cpu_alarm_high-rjpk5urpcoym |
| ok_actions | None |
| project_id | bf90981532444f91b70d3f58e9fd1b3d |
| query | {"=": {"server_group": "d65c891b-4543-4d1e-aa39-4d446ce4a3e8"}} |
| repeat_actions | True |
| resource_type | instance |
| severity | low |
| state | insufficient data |
| threshold | 50.0 |
| type | gnocchi_aggregation_by_resources_threshold |
| user_id | e4affad987524aa1bf5a782e939efb65 |
+---------------------------+--------------------------------------------------------------------------+
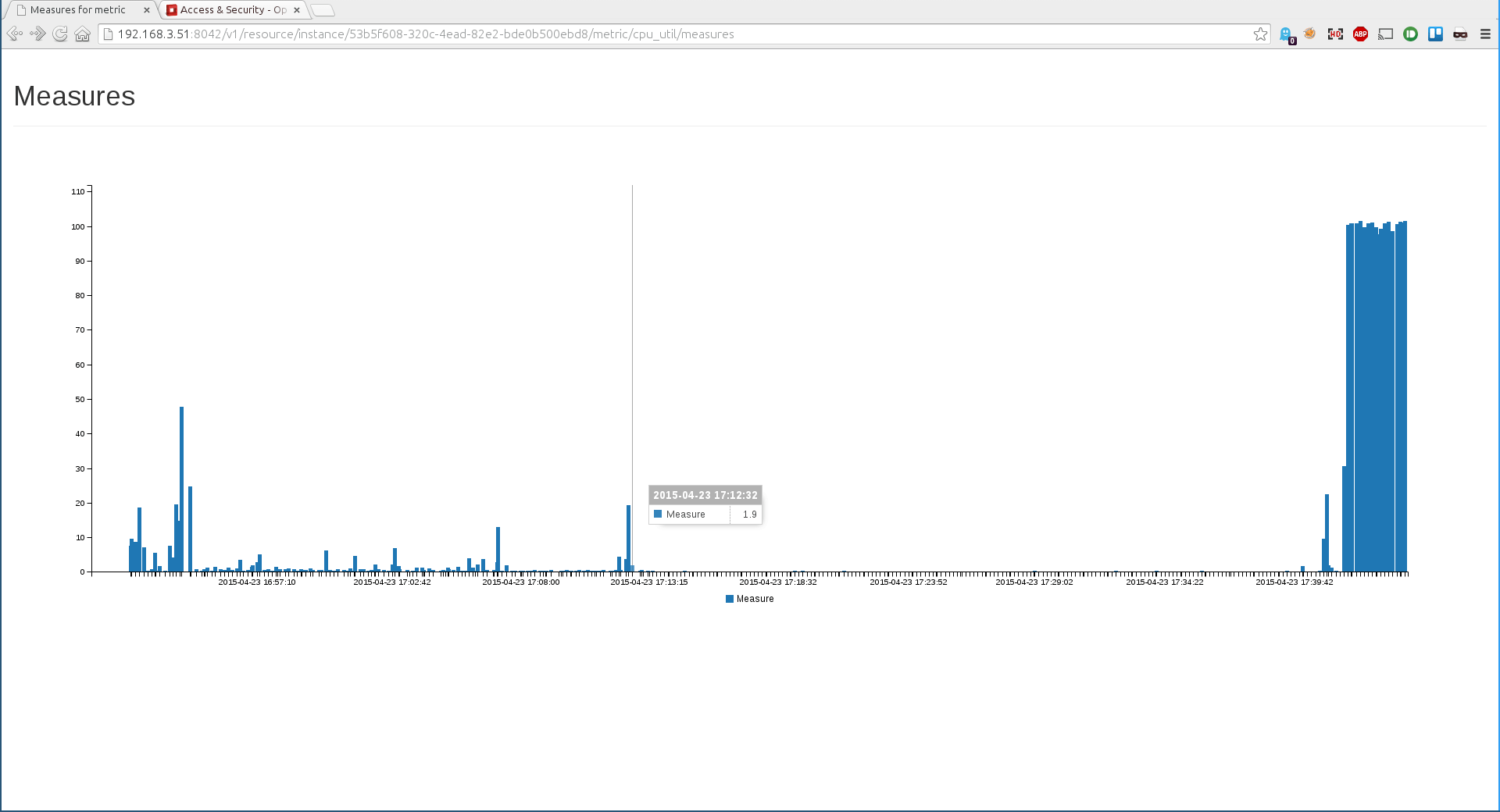
Gnocchi provides some basic graphing view of resources. For now this is mainly for development/debugging purpose. To access it when the keystone middleware is enabled, you can inject the token to all your requests using this:
$ sudo pip install mitmproxy $ source devstack/openrc admin admin $ token=$(openstack token issue -f value -c id) $ mitmproxy -p 8042 -R http2http://localhost:8041/ --setheader ":~hq:X-Auth-Token: $token"
And then point your browser to a resource URL on the port 8042 of your devstack:
- cpu_util of the first instance:
http://localhost:8042/v1/resource/instance/53b5f608-320c-4ead-82e2-bde0b500ebd8/metric/cpu_util/measures
[…] you can build applications which know when they need more resources and scale automatically. In this tutorial from Mehdi Abaakouk, get started with the […]
I wonder which version of devstack used? I tried to enable the heat, ceilometer and gnocchi services in local.conf, but I had an error after stack.sh command: “The ‘pycadf = 0.8.0’ distribution was not found and is required by keystone “